|
Włodzisław Duch |
 |
|
Włodzisław Duch |
|
With thanks to Rafał Adamczak, Karol Grudziński, Antoine Naud, Krzysztof Grąbczewski and Norbert Jankowski.

Some papers are in our on-line archive:
Use of various forms of knowledge in one system is still an open question.
Some methods developed in our group:
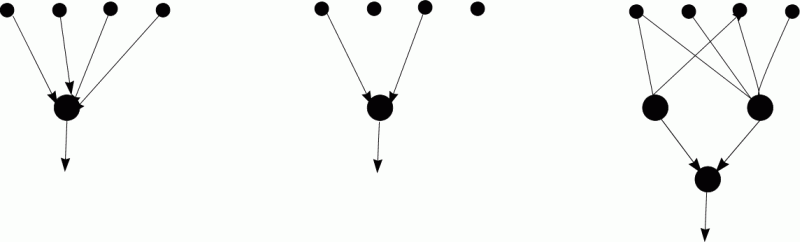
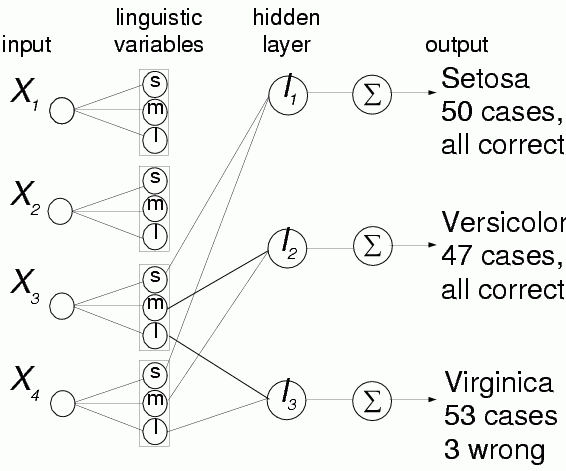
Architecture: Aggregation, Linguistic variables and Rule layers; one oputput per class.
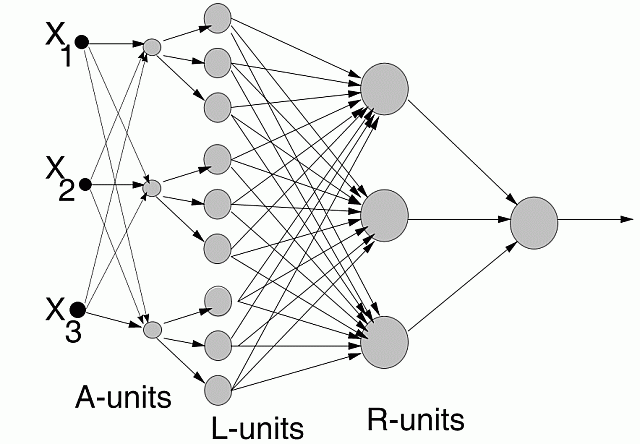
Aggregation: used to combine and discover new useful features, no constraints.
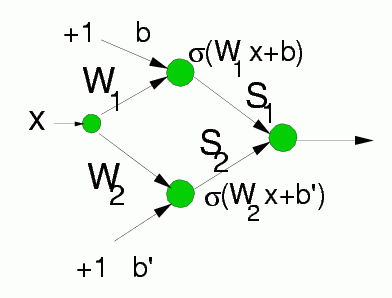
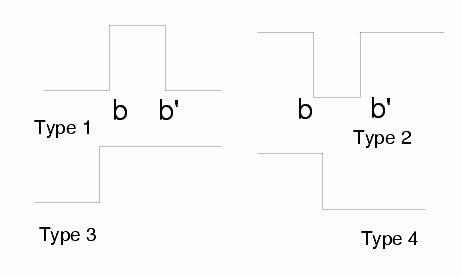
L-units: providing intervals for fuzzy or crisp membership functions, made from 2 neurons, only biases are adaptive parameters here.
Constraint MLP cost function
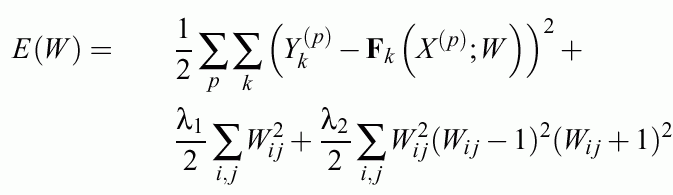
First term: standard quadratic function (or any other)
Second term: weight decay & feature selection.
Third term: from complex to simple hypercuboidal classification decision regions for crisp logic (for steep
sigmoids).
Different regularizers and different error functions may be used.
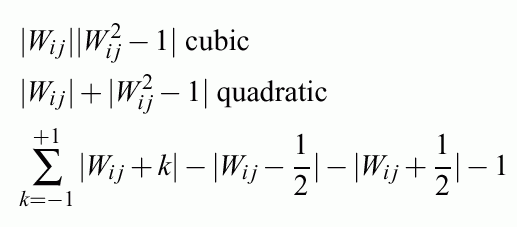
Logical rules from MLP: simplify the network by enforcing weight decay and other constraints.
Strong and weak regularization allows to explore simplicity-accuracy tradeoff.
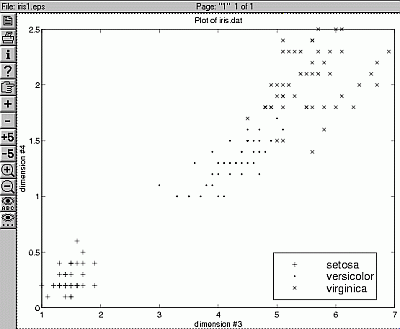
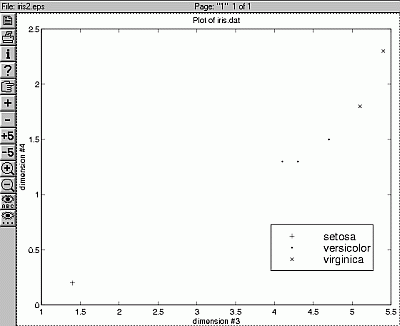
Network generated for the Iris problem; the simplest (for strongest regularization) uses only x3.
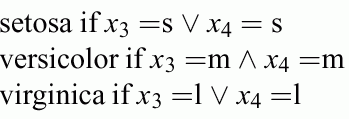
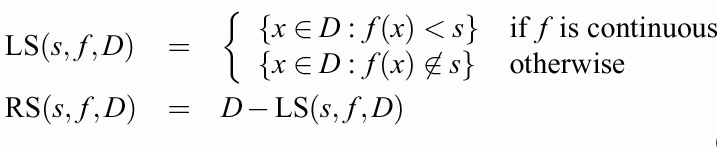
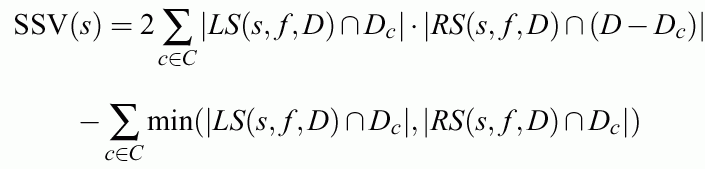
Selection of the best prototypes - "supermans".
Rules possible with:
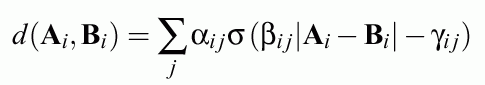
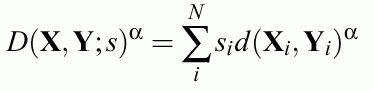
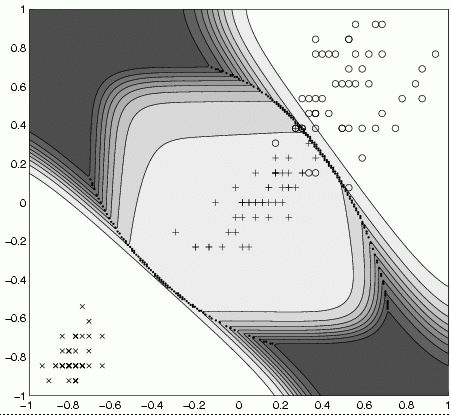
Regularization of models allows to exploresimplicity-accuracy tradeoff.
Next step: exploring the confidence-rejection rate tradeoff.
Weighted combination of "predictive power" of rules and the number of errors:
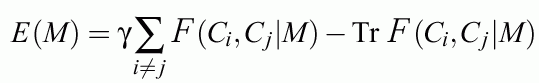
should be minimized without constraints, with optional risk matrix

This cost function allows to reduce the number of errors to zero (large gamma) for models M that reject some instances.
Data from measurements/observations is not precise.
Finite resolution: Gaussian error distribution:
x -> Gx=G(y;x,sx), where Gx is a Gaussian (fuzzy) number.
Given a set of logical rules {Â} apply them to input data {Gx
}.
Use Monte Carlo sampling to recover p(Ci | X; {Â
}) - may be used with any classifier.
Analytical estimation of this probability is based on cumulant function:

Approximation better than 2%. Probability that the rule is true:
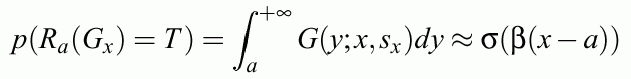
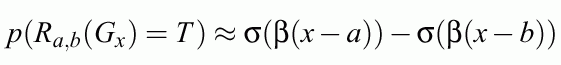
Soft trapezoidal membership functions realized by L-units are obtained.
Fuzzy logic with such functions is equivalent to classical logic with Gaussian numbers as input and neural
networks with logistic transfer functions.
This is not a fuzzy approach!
Here small receptive fields are used, in fuzzy approach typically 2-3 large receptive fields define linguistic
variables.
Benefits:


The Mushroom Guide clearly states that there is no simple rule for determining the edibility of these mushrooms; no rule like “leaflets three, let it be“ for Poisonous Oak and Ivy.
8124 cases, 22 symbolic attributes, up to 12 values each, equivalent to 118 logical features.
51.8% represent edible, the rest non-edible mushrooms.
Example:
edible, convex, fibrous, yellow, bruises, anise, free, crowded, narrow, brown, tapering, bulbous, smooth, smooth, white, white, partial, white, one, pendant, purple, several, woods
poisonous, convex, smooth, white, bruises, pungent, free, close, narrow, white, enlarging, equal, smooth, smooth, white, white, partial, white, one, pendant, black, scattered, urban
Safe rule for edible mushrooms:
| odor = (almond.or.anise.or.none) Ù spore-print-color = Ø green | 48 errors, 99.41% correct |
| This is why animals have such a good sense of smell! | |
| Other odors: creosote, fishy, foul, musty, pungent or spicy | |
Rules for poisonous mushrooms - 6 attributes only | |
| R1) odor = Ø (almond Ú anise Ú none); | 120 errors, 98.52% |
| R2) spore-print-color = green | 48 errors, 99.41% correct |
| R3) odor = none Ù
stalk-surface-below-ring = scaly Ù stalk- color-above-ring = Ø brown | 8 errors, 99.90% |
| R4) habitat = leaves Ùcap-color = white | no errors! |
R1 + R2 are quite stable, found even with 10% of data;
R3 and R4 may be replaced by other rules:
R'3): gill-size = narrow Ù stalk-surface-above-ring = (silky
Ú scaly)
R'4): gill-size = narrow Ù population = clustered
Only 5 attributes used !
286 cases, 201 no recurrence cancer events (70.3%), 85 are recurrence (29.7%) events.
9 attributes, symbolic with 2 to 13 values.
Single rule:

with else condition gives over 77% in crossvalidation; best systems do not exceed 78%. All knowledge contained in the data is:
if more than 2 nodes were involved and it is highly malignant there will be recurrence.
699 cases, 458 benign (65.5%), 241 (34.5%) malignant.
9 attributes, integers 1-10, one attribute missing in 16 cases.
The simplest rules, large regularization:
IF f2 ł 7 Ú f7 ł 6 THEN malignant (95.6%)
Overall accuracy (including ELSE condition) is 94.9%.
f2 - uniformity of cell size; f7 - bland chromatin
Hierarchical sets of rules with increasing accuracy may be build
More accurate set of rules:
R1: f2<6 Ù f4<3 Ù f8<8 | (99.8)% |
| R2: f2<9 Ù f5<4 Ù f7<2 Ù f8<5 | (100)% |
| R3: f2<10 Ù f4<4 Ù f5<4 Ù f7<3 | (100)% |
| R4: f2<7 Ù f4<9 Ù f5<3 Ù f7Î [4,9] Ù f8<4 | (100)% |
| R5: f2Î [3,4]Ù f4<9 Ù f5<10 Ù f7<6 Ù f8<8 | (99.8)% |
R1 and R5 misclassify the same 1 benign vector.
ELSE condition makes 6 errors, overall reclassification accuracy 99.00%
In all cases features f3 and f6 (uniformity of cell shape and bare nuclei) are not important, f2 and f7 being the most important.
100% reliable set of rules rejects 51 cases (7.3%).
Results from the 10-fold (stratified) crossvalidation - accuracy of rules is hard to compare without the test set
| Method | % accuracy |
| IncNet | 97.1 |
| 3-NN, Manhattan | 97.1ą 0.1 |
| Fisher LDA | 96.8 |
| MLP+backpropagation | 96.7 |
| LVQ (vector quantization) | 96.6 |
| Bayes (pairwise dependent) | 96.6 |
| FSM (density estimation) | 96.5 |
| Naive Bayes | 96.4 |
| Linear Discriminant Analysis | 96.0 |
| RBF | 95.9 |
| CART (decision tree) | 94.2 |
| LFC, ASI, ASR (decision trees) | 94.4-95.6 |
| Quadratic Discriminant Analysis | 34.5 |
Data from Machine Learning Database repository, UCI
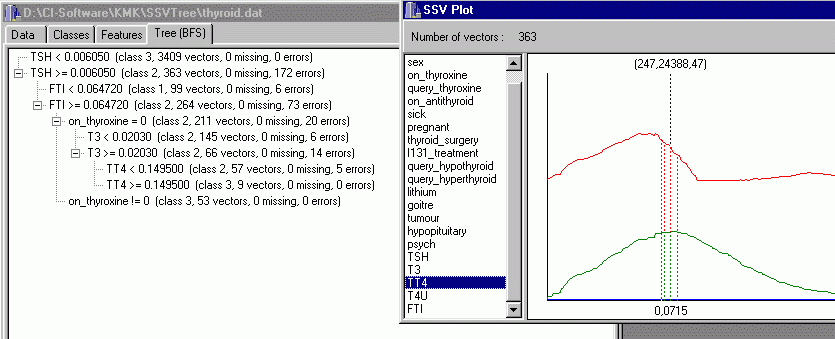
3 classes: hypothyroid, hiperthyroid, normal;
# training vectors 3772 = 93+191+3488
# test vectors 3428 = 73+177+3178
21 attributes (medical tests), 6 continuos
Optimized rules: 4 errors on the training set (99.89%), 22 errors on the test set (99.36%)
| primary hypothyroid: | TSH>30.48 & FTI <64.27 | 97.06% |
| primary hypothyroid: | TSH=[6.02,29.53] & FTI <64.27 & T3< 23.22 | 100% |
| compensated: | TSH > 6.02 & FTI>[64.27,186.71] & TT4=[50, 150.5) &
On_Tyroxin=no & surgery=no | 98.96% |
| no hypothyroid: | ELSE | 100% |
4 continuos attributes used and 2 binary.
| Method | Reference | ||
| C-MLP2LN rules + ASA | | | our group |
| CART | | | Weiss |
| PVM | | | Weiss |
| IncNet | | |
our group |
| MLP init+ a,b opt. | | | our group |
| C-MLP2LN rules | | |
our group |
| Cascade correlation | | | Schiffmann |
| BP + local adapt. rates | | | Schiffmann |
| BP+genetic opt. | | |
Schiffmann |
| Quickprop | | | Schiffmann |
| RPROP | | | Schiffmann |
| 3-NN, Euclides, 3 features used | | | our group |
| 1-NN, Euclides, 3 features used | | | our group |
| Best backpropagation | | | Schiffmann |
| 1-NN, Euclides, 8 features used | |
| our group |
| Bayesian classif. | | |
Weiss |
| BP+conjugate gradient | | |
Schiffmann |
| 1-NN Manhattan, std data | | our group | |
| default: 250 test errors | | ||
| 1-NN Manhattan, raw data | | our group |
Training set 43500, test set 14500, 9 attributes, 7 classes
Approximately 80% of the data belongs to class 1, only 6 vectors in class 6.
Rules from FSM after optimization: 15 rules, train 99.89%, test 99.81% accuracy.
32 rules obtained from SSV give 100% train, 99.99% test accuracy (1 error).
| Method | % training | % test | Reference |
| SSV, 32 rules | 100 | 99.99 | our group |
| NewID decision tree | 100 | 99.99 | Statlog |
| Baytree decision tree | 100 | 99.98 | Statlog |
| CN2 decision tree | 100 | 99.97 | Statlog |
| CART | 99.96 | 99.92 | Statlog |
| C4.5 | 99.96 | 99.90 | Statlog |
| FSM, 15 rules | 99.89 | 99.81 | our group |
| MLP | 95.50 | 99.57 | Statlog |
| k-NN | 99.61 | 99.56 | Statlog |
| RBF | 98.40 | 98.60 | Statlog |
| Logistic DA | 96.06 | 96.17 | Statlog |
| LDA | 95.02 | 95.17 | Statlog |
| Naive Bayes | 95.40 | 95.50 | Statlog |
| Default | 78.41 | 79.16 |
More examples of logical rules discovered are on our rule-extraction WWW page
Ghostminer project (sponsored by Fujitsu): datamining package, composed of:
Example of final product: analysis of psychometric data
MMPI test has 550 questions; any similar test may be computerized.
MMPI scales 1-4 used for control, next 10 coefficients are clinical scales: hypochondria, depression, hysteria, psychopathy, paranoia, schizophrenia etc. |  |
Display scales in a “psychogram”, interpreted by skilled psychologists diagnosing specific problems; show rules that are true for this case. Rules are derived from data collected in the Academic Psychological Clinic of Nicolaus Copernicus University and in several psychiatric hospitals around Poland. | 
|
Two datasets used, woman and man, over 1600 cases each, 27 classes (normal, neurotic, drug addicts, schizophrenic, psychopaths, organic problems, malingerers, persons with criminal tendencies etc.).
2-3 rules per class found, a total of 50-100 rules.
Analyze how each rule fits to the case; vary uncertainty of input measurement (optimal uncertainty has been calculated by minimization of generalization error). | 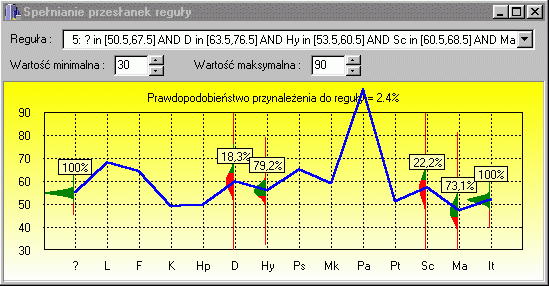
|
Show probabilities of different diagnoses, graph their dependence on the uncertainity of inputs. | 
|
Show verbal interpretation of cases and rules. | 
|
If probability of new classes quickly grows with the assumed uncertainty of the measurement analyze probabilistic confidence levels. | 
|
Multidimensional scaling (MDS) allows to see the case in relation to known cases.
Probabilities of different diagnoses may be interpolated to show change of the mental health over time.
Probabilistic confidence levels allow to see detailed changes.
Rules are very important here, allowing for detailed interpretation.
Rules generated using SSV classification tree and FSM neural network.
|
System | Data | # rules | Accuracy | Fuzzy |
| C4.5 | Women | 55 | 93.0% | 93.7% |
| Men | 61 | 92.5% | 93.1% | |
| FSM | Women | 69 | 95.4% | 97.6% |
| Men | 98 | 95.9% | 96.9% |
10-fold crossvalidation gives 82-85% correct answers with FSM (crisp unoptimized rules), and 79-84% correct answers with C4.5. Fuzzification improves FSM crossvalidation results to 90-92%.
Some questions:
How good are our experts?
How to measure the correctness of such system?
Can we provide useful information if diagnosis is not reliable?
How to deal with several disease - automatic creation of new classes?
In real world projects training and finding optimal networks is not our hardest problem ...
Discovering hierarchical structure in the data.
Dealing with unknown (unmeasured or lost) values.
Constructing new, more useful features.
Constructing theories allowing to reason about data.
Constructing new and modifying exising classes.
Building complex systems interacting with humans.
References:
IEEE TNN paper (2000, did not make it to the data mining issue but perhaps the next?);
IJCNN'2000 Tutorial
{kind=link}
{kind=link}
{kind=link}