|
Norbert Jankowski, Krzysztof Grąbczewski, Rafał Adamczak |
 |
|
Norbert Jankowski, Krzysztof Grąbczewski, Rafał Adamczak |
|



Are rules indeed the only way to understand the data?
What type of explanation is satisfactory? Interesting cognitive psychology problem.
Knowledge accessible to humans: symbols, similarity to prototypes, visualization.
Psychology: examplar and prototype theories of categorization; rules only in logic is simple.
Crisp logical rules are most desirable but ...

Fuzzy rules - continuous membership functions.

Fixed set of membership functions with predetermined shapes - bad idea.
Curse of dimensionality: k linguistic variables in d dimensions gives kd areas.

Context-dependent linguistic variables - adapt membership functions in each rule.
Interpretation of crisp rules may be misleading.
Crisp rules may be unstable against small perturbations of input values.
Statisticians: rule-based classifiers are unstable.
Probabilities estimated using fuzzy rules change smoothly.
How to find the best fuzziness/precision tradeoff ?
How to understand what the best classifier is doing?

Methodology of rule extraction:
This approach leads to the following important improvements for any rule-based system:
IF probability of new classes quickly grows (here from 0-33%) with the assumed uncertainty of the measurement (here between 0-3%)
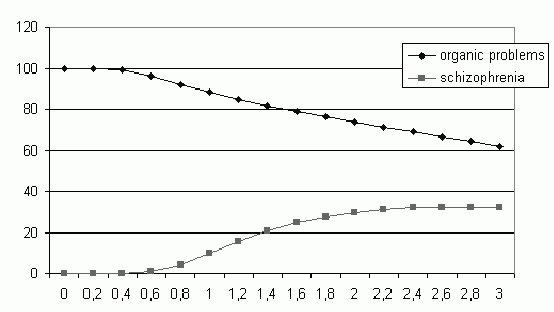
THEN analyze probabilistic confidence levels.
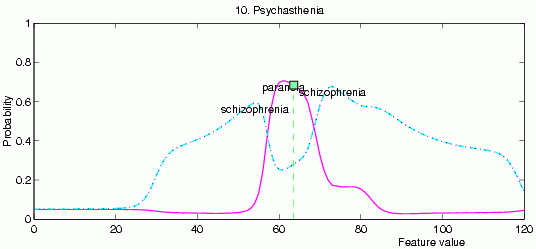
Probabilities of different diagnoses may be interpolated to show change of the mental health over time.
Probabilistic confidence levels allow to see detailed changes.
There are many ways to understand the data: rules, prototypes, visualization.
Only reliable, accurate, stable and sufficiently simple rules are useful.
Unstable sets of rules contain little useful information and may be misleading.
Simplicity/accuracy rate tradeoff should be explored.
Optimization of sets of rules allows to explore reliability/rejection rate tradeoff.
Classification probabilities are important, rules are not sufficient.
The neigborhood of the unknown input should always be explored.
Probabilities of classification should be parametrized by uncertainties of inputs.
Probabilistic confidence intervals enable detailed interpretation of cases.
Exploratory data analysis (visualization) is always worth using.
These methods may be used with any classifier, so why not use the best one?
